



I've been trying out Porter recently and it has been an overall great experience. The team is diligently working on improving the product and helping their users.
For me I am interested in the Jobs aspect (tasks that only run when an operator clicks on them or through a cron schedule), more than web services or long running processes.
Historically, jobs have taken a second class role to their older siblings of web services and long running processes (long running processes are somewhat just web servers that don't have a http listen port). An example of this is seen in how GCP functions as a service have time limits of 540 seconds, and although google cloud run bumps this limit it is capped to around an hour (at the time of writing). Jobs may need to run longer than that and need a UX to support how operators traditionally use them (a dashboard push button with easy to read logs).
Kubernetes is a good fit for this use case, but often it is something that causes dread with how difficult it is to maintain and operate (let alone lack of any easy to use UI). Porter leverages the strengths of job management and execution engine of Kubernetes while offering a solid DX/UX for end users. Some of the benefits they add are:
- Automatic container management
- Automatic deployment and setup on customer cloud even if you've never used Kubernetes before
- Building in the open and a supportive and helpful community
- Clear logs next to running processes
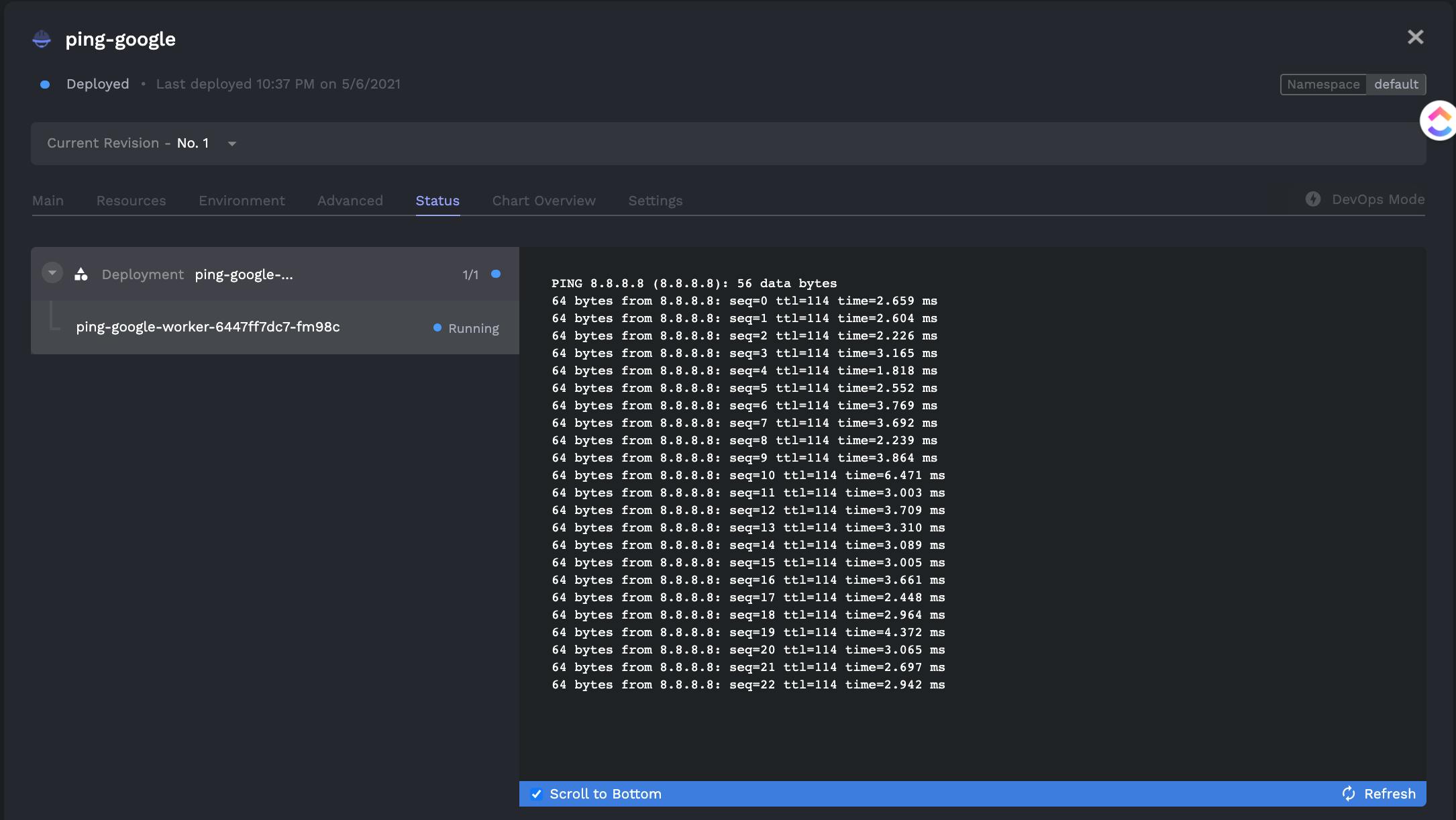
- Beautiful UX for monitoring your processes:
Taking a step back from porter, here are some needs of most job / task running platforms:
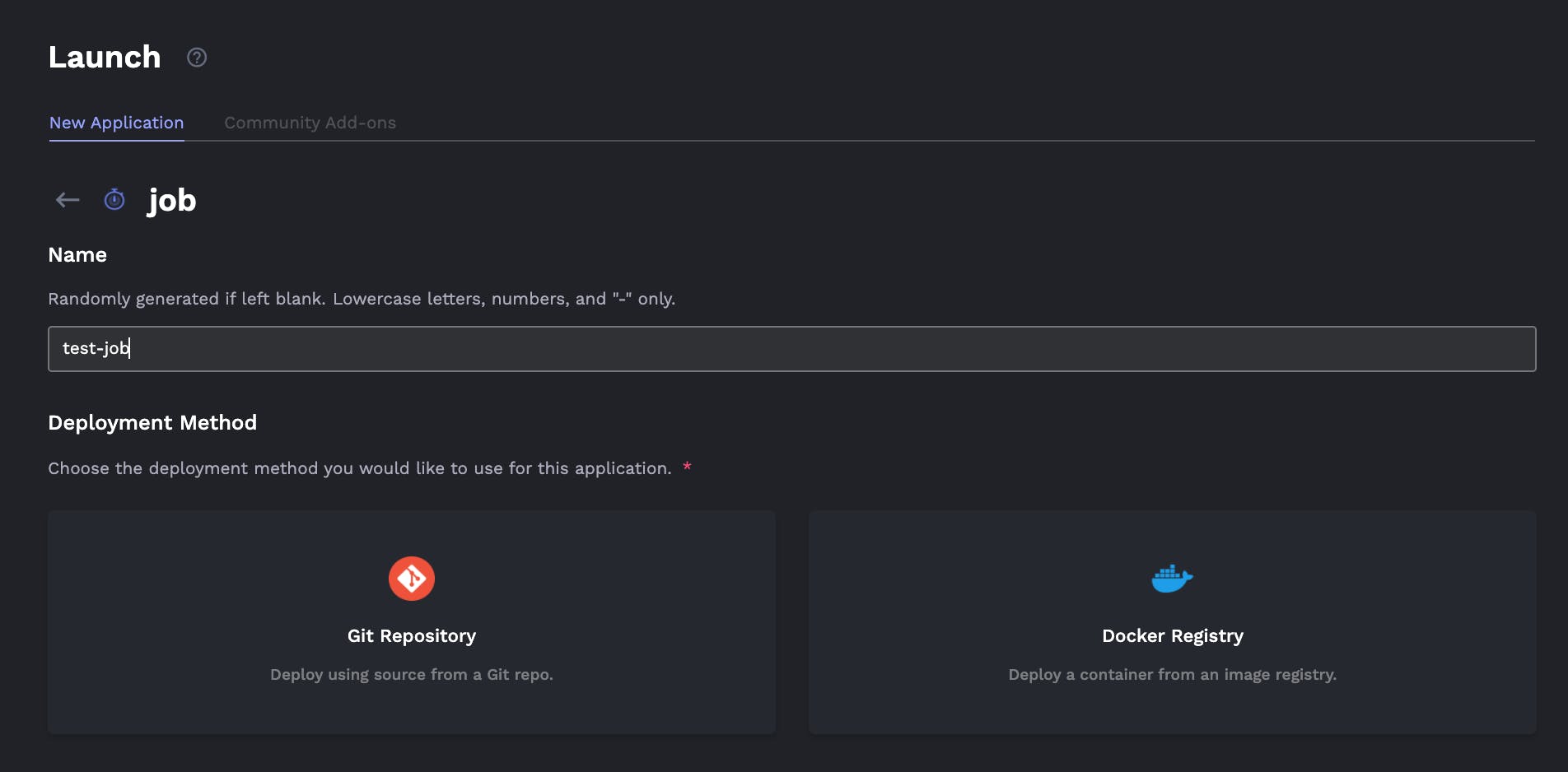
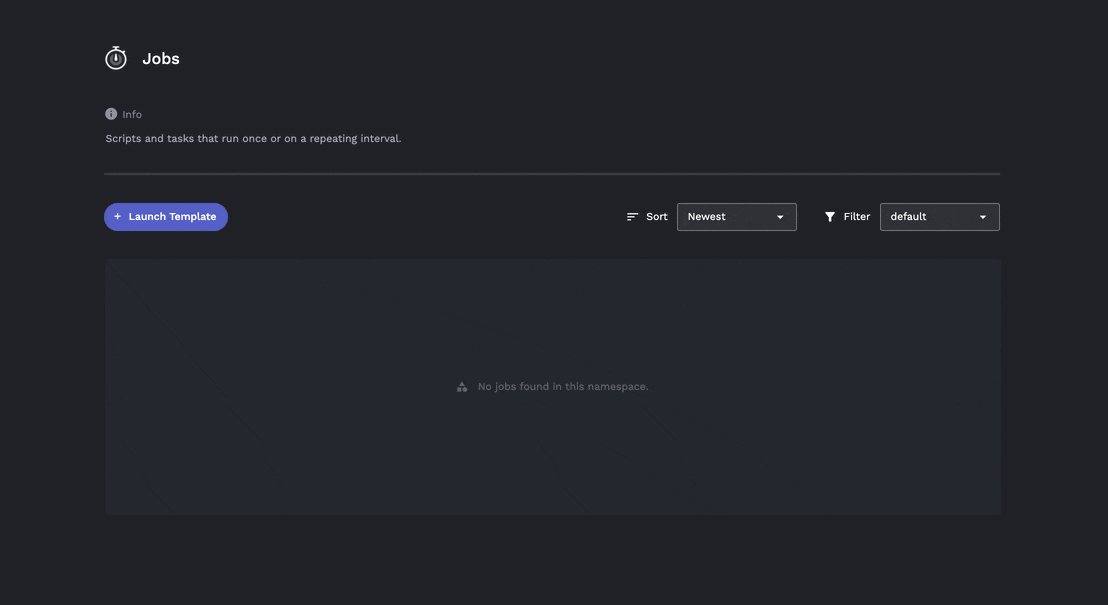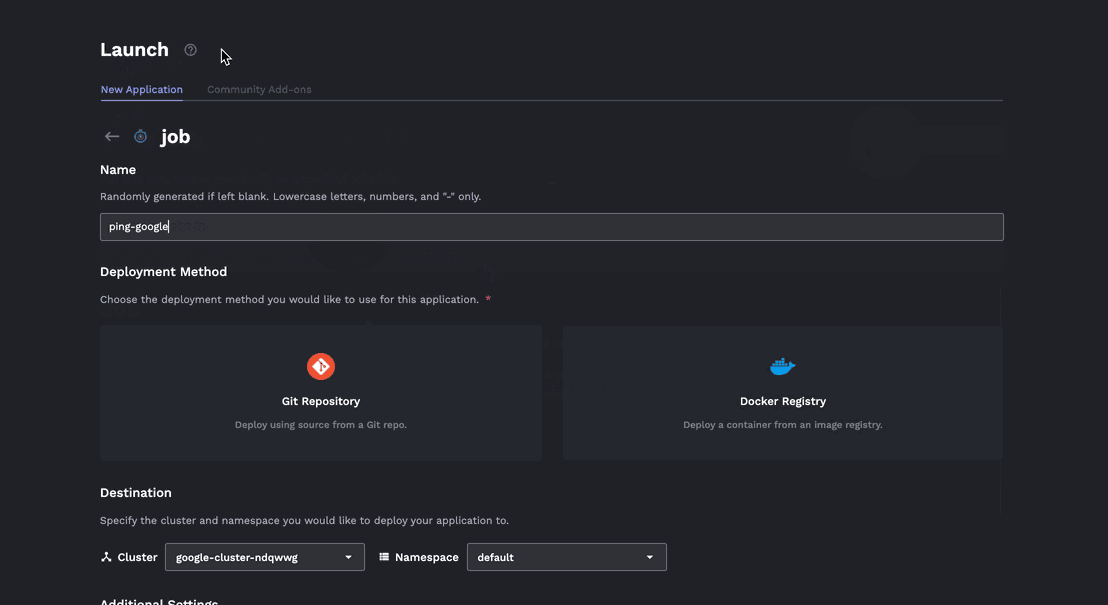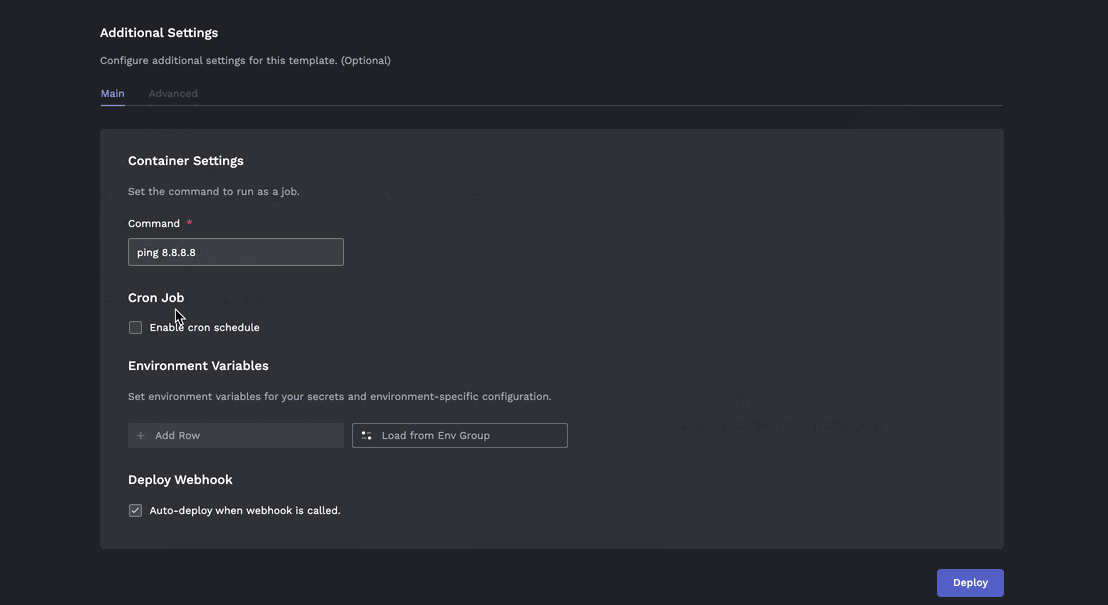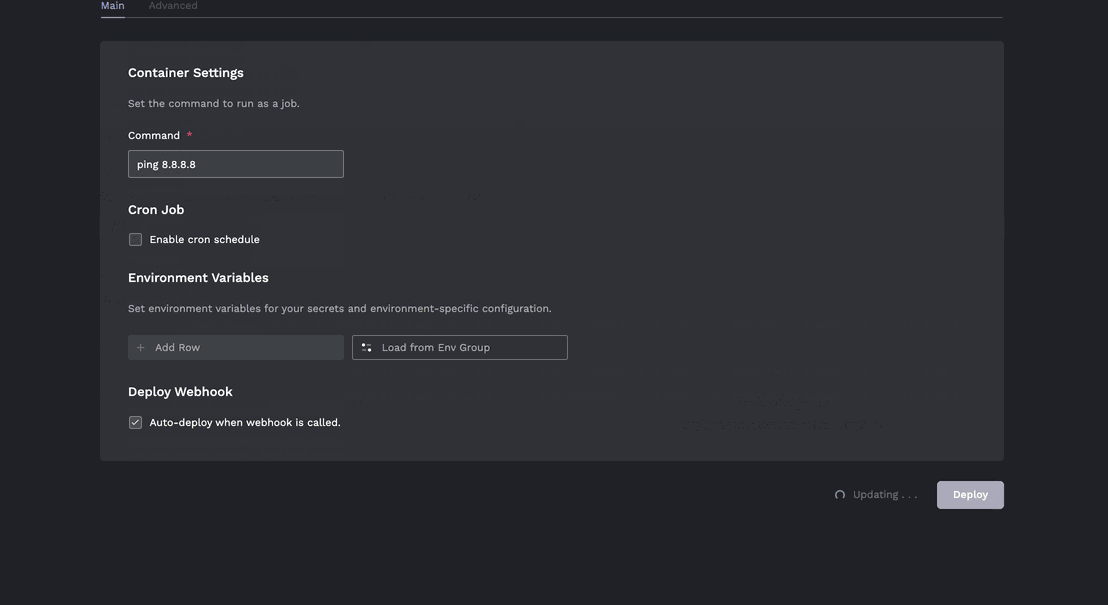
- Jobs can be created easily from a Docker container or better yet a git repo:
- Jobs can be scheduled on a cron recurrence.
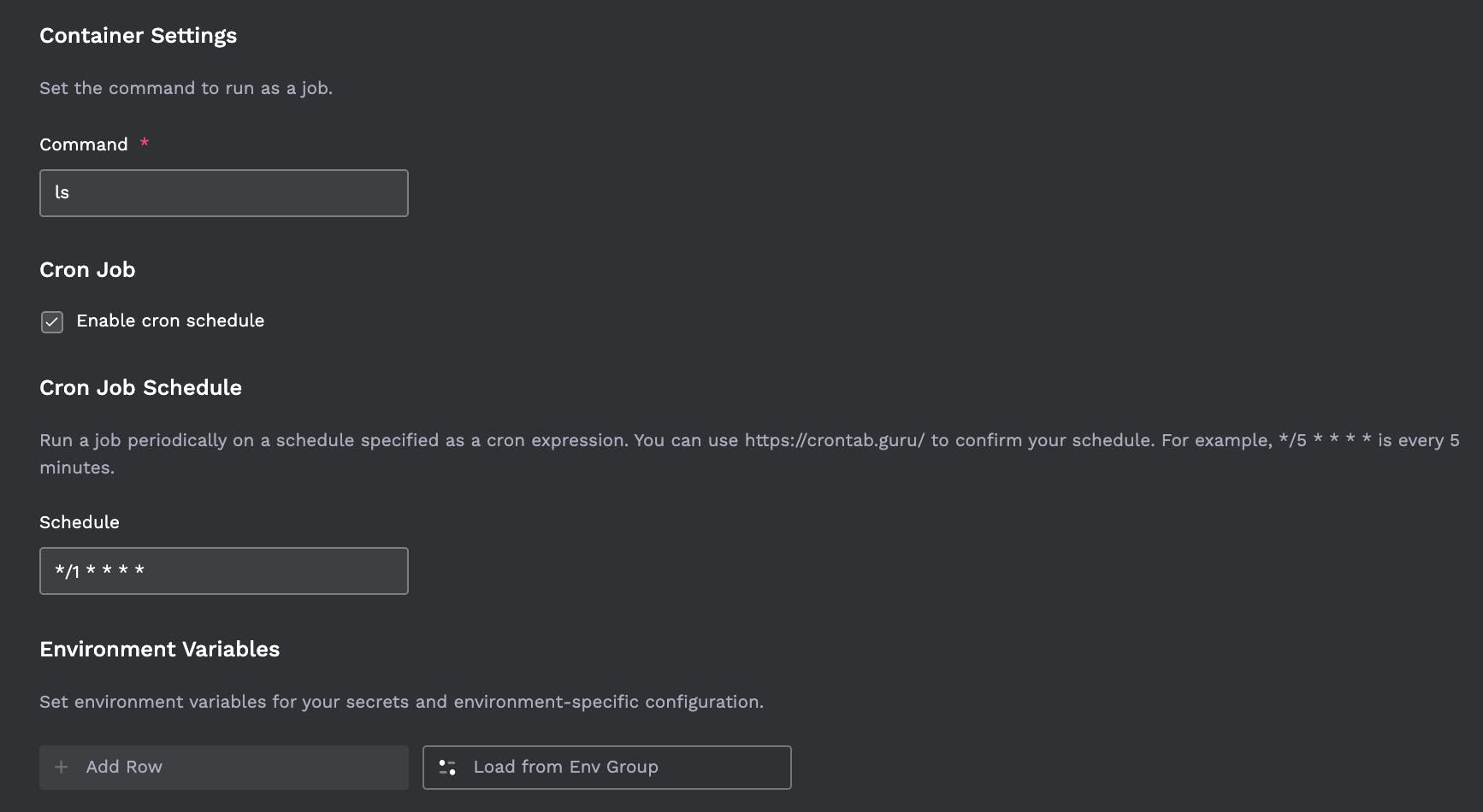
Here's a quick gif showing that workflow in porter:
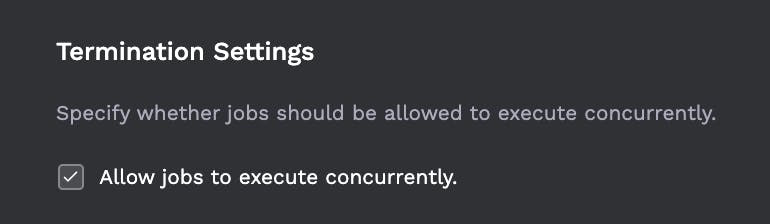
- Jobs can be configured to not run over each other (or configured to proceed even if another job is running). For example if a job is set to run every minute but for some reason its slower now and takes 5 minutes, it should block other jobs from being spawned until complete.
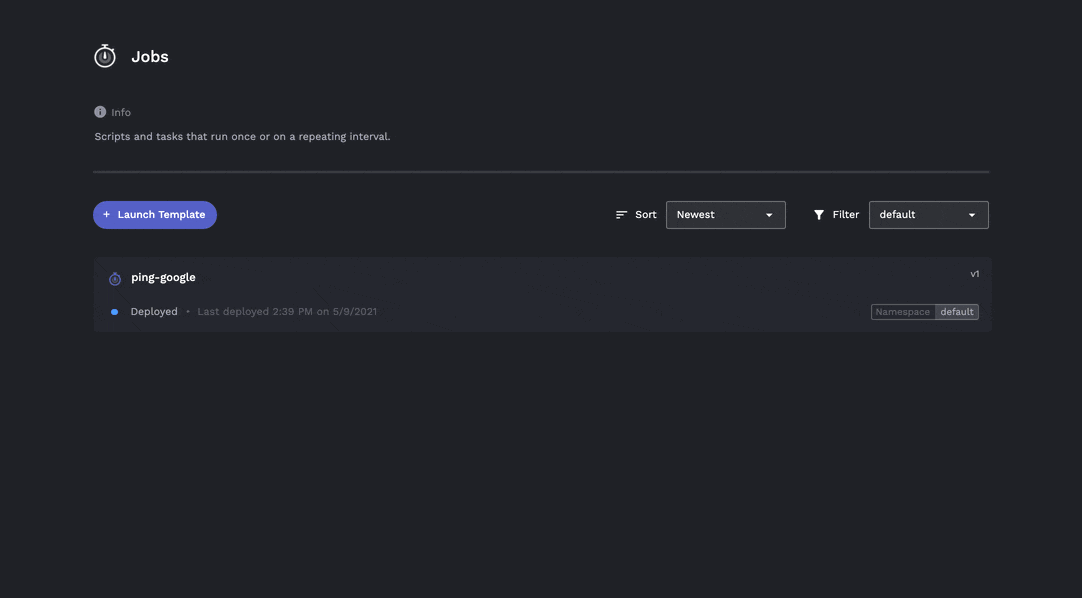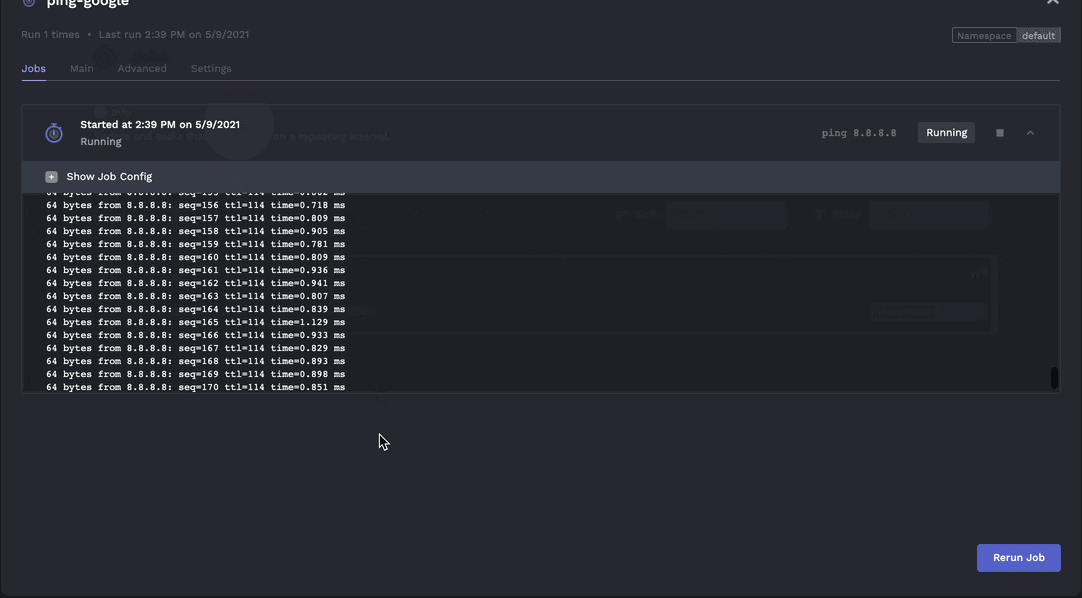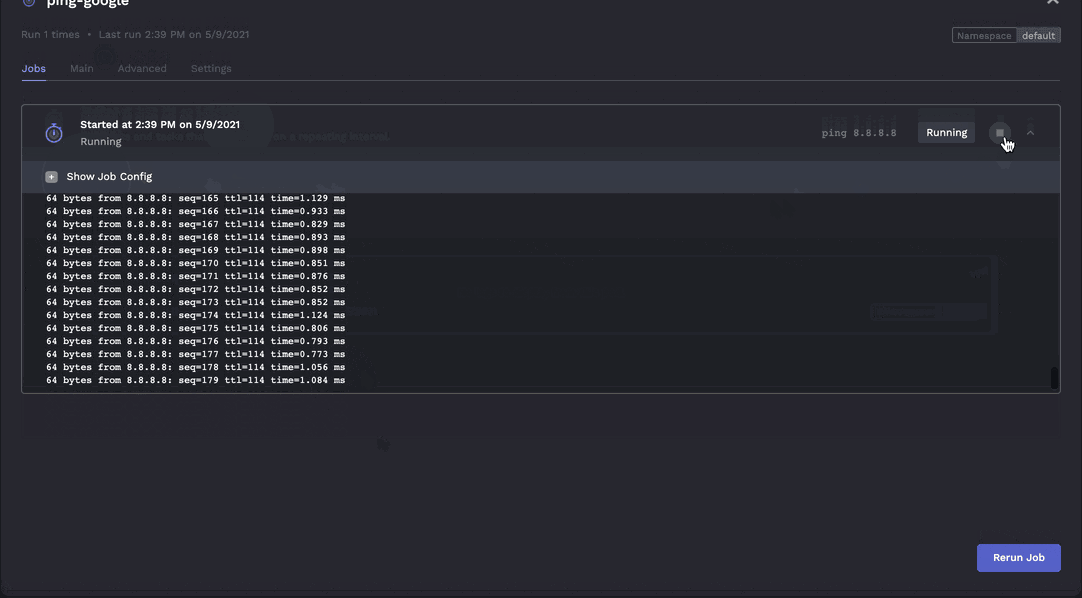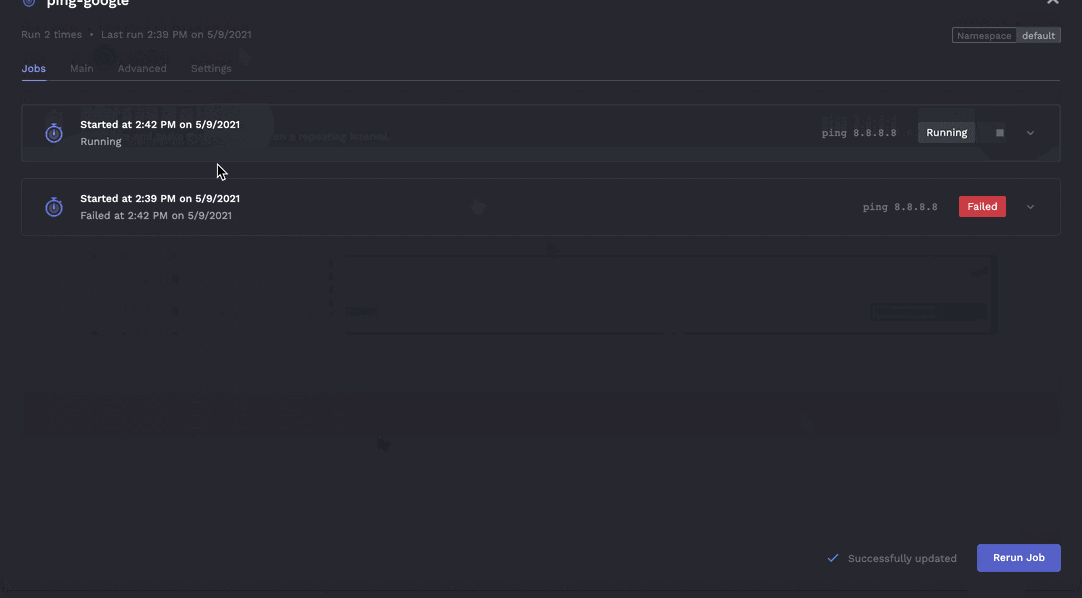
Jobs should stream logs in realtime so you can see how progress is going.
Jobs can be stopped on demand.
- Jobs should be able to be changed after the fact (specifically the run command, environment variables, cron schedule). For example when debugging a job you may need to change the logging level temporarily and see whats going on. Once resolved you can turn down the log levels again.
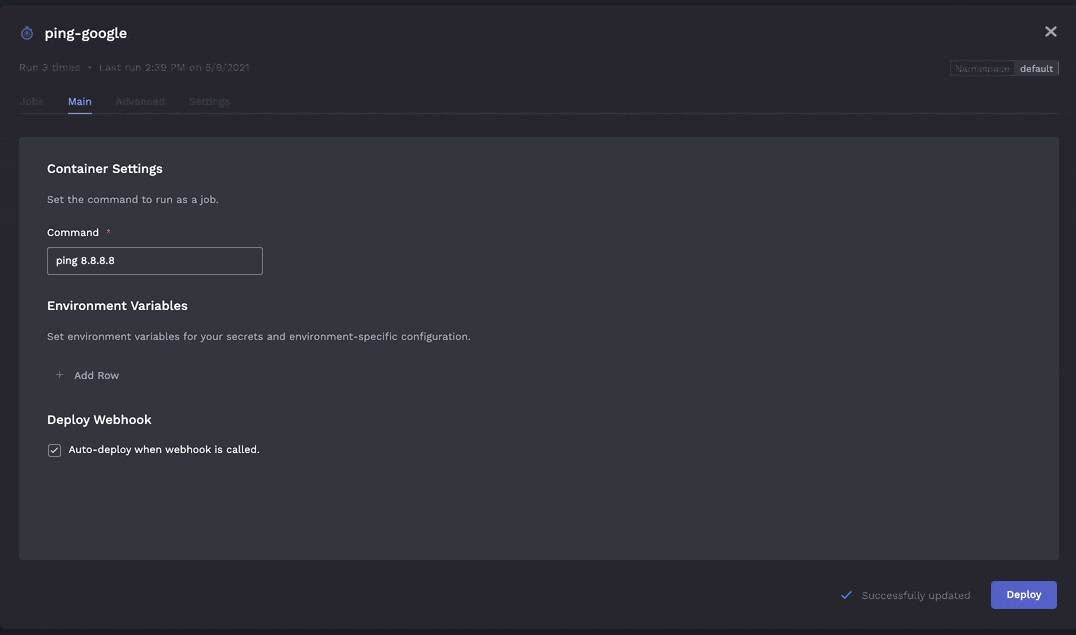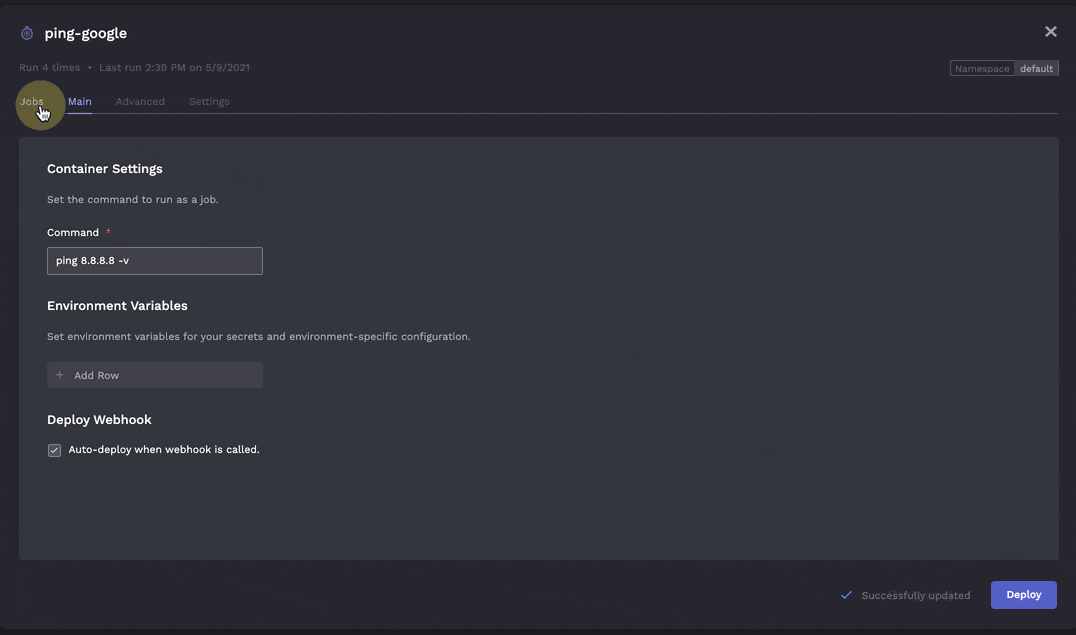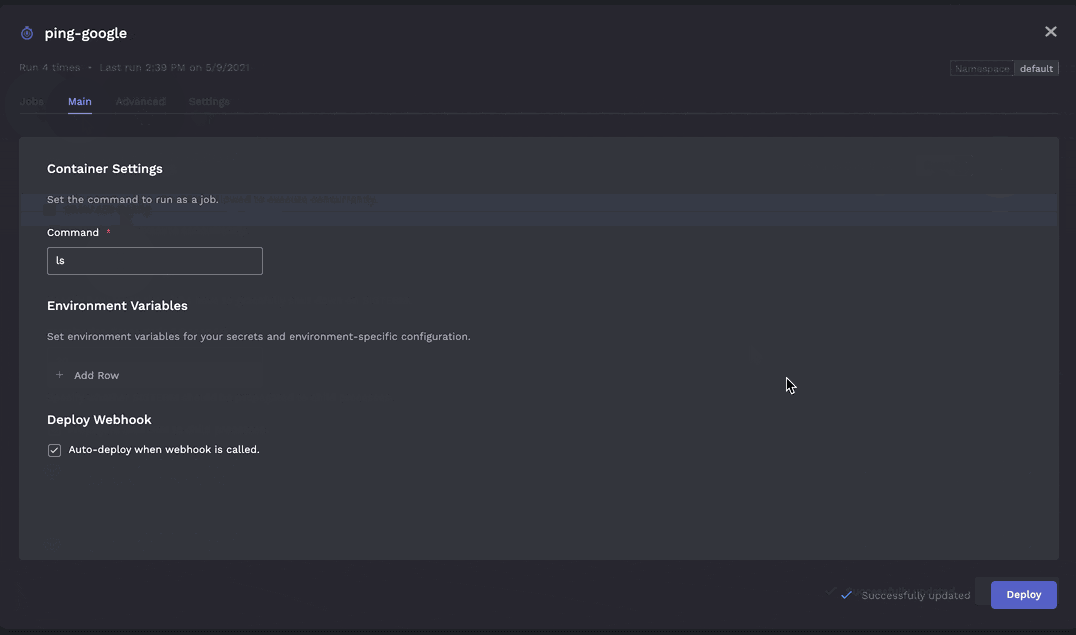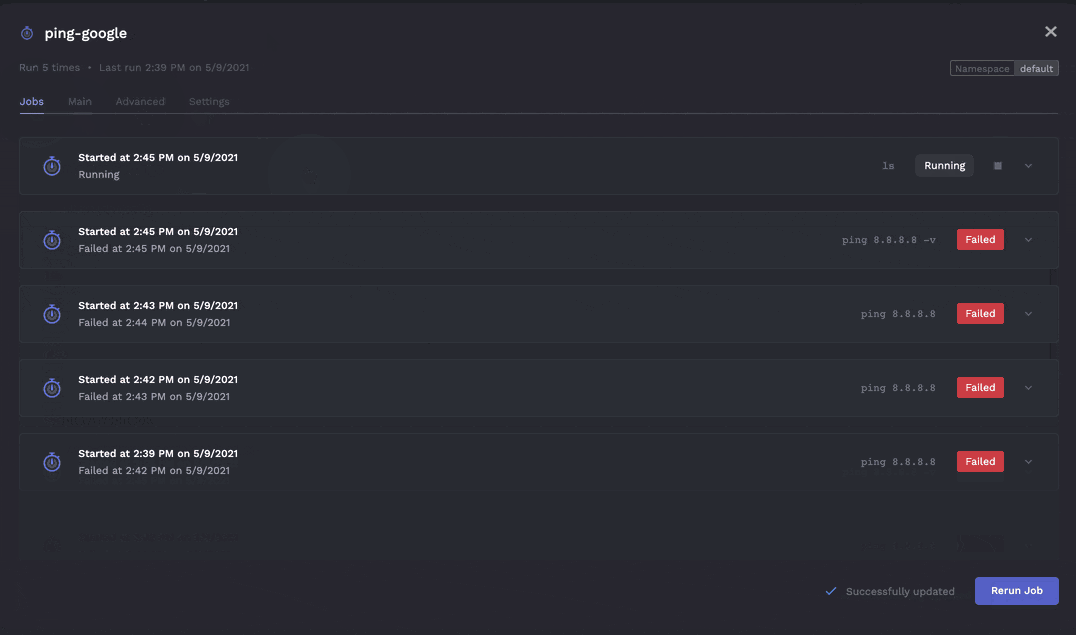
Currently although run commands and envvars can be changed the cron schedule cannot unfortunately (but this unlocks an interesting use case described further below - a cron job that never runs due to running on Feb 31st is effectively a job)
- Clear understanding of historical job runs / logs.
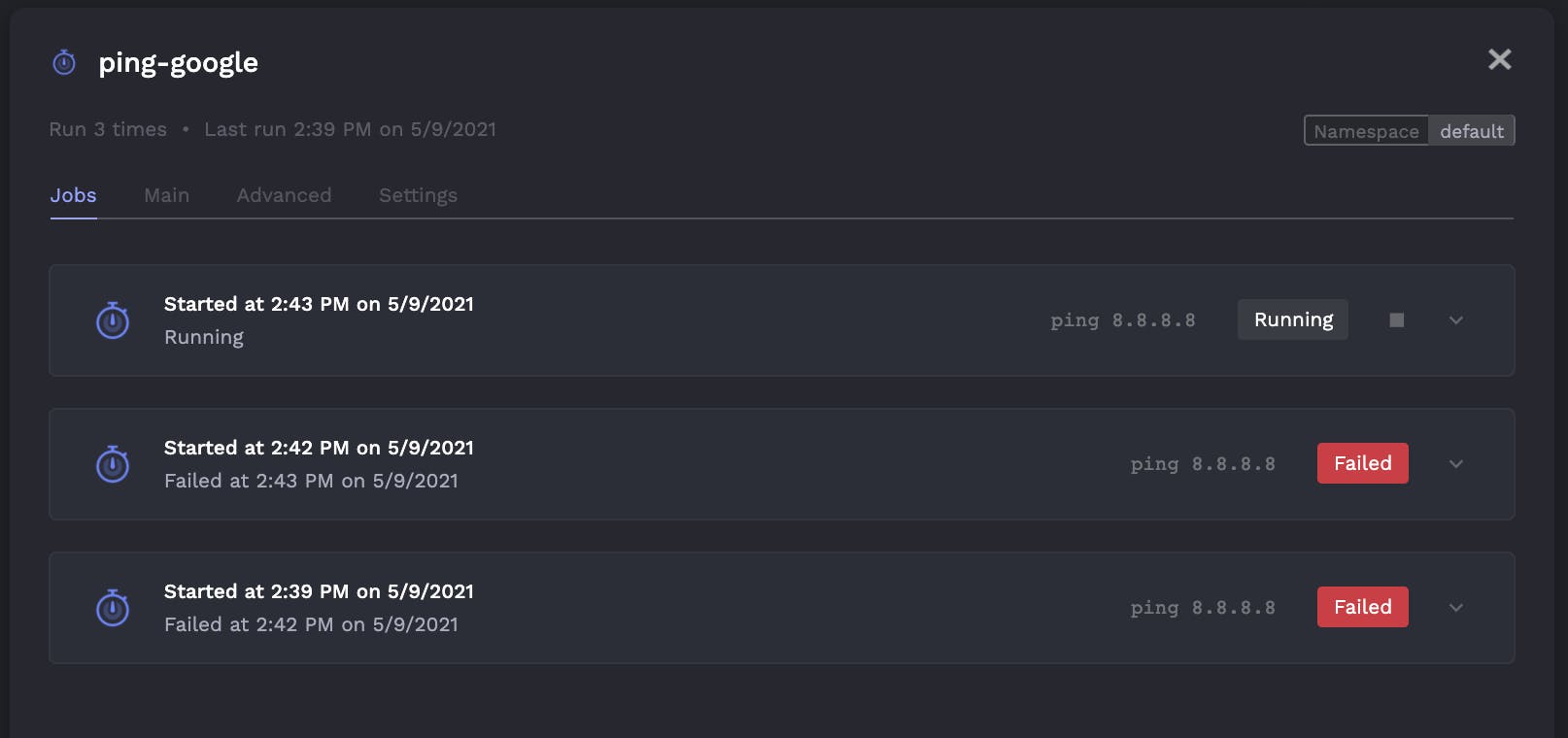
The above is a view of all runs of a single job. However an area for improvement is when looking at all jobs it can be hard to find what you're looking for. Porter should have the ability to group by folders or have tags you can filter through (maybe you can use kubernetes namespaces, but I think thats still not the right fit).
- Jobs can be deployed and released from a CI/CD pipeline such as github actions.
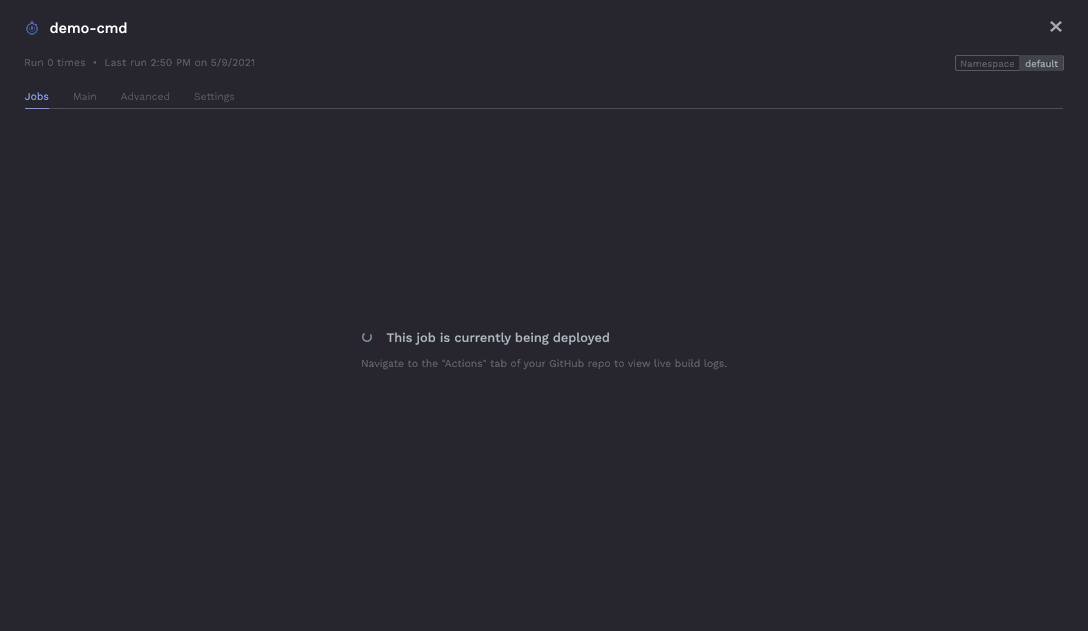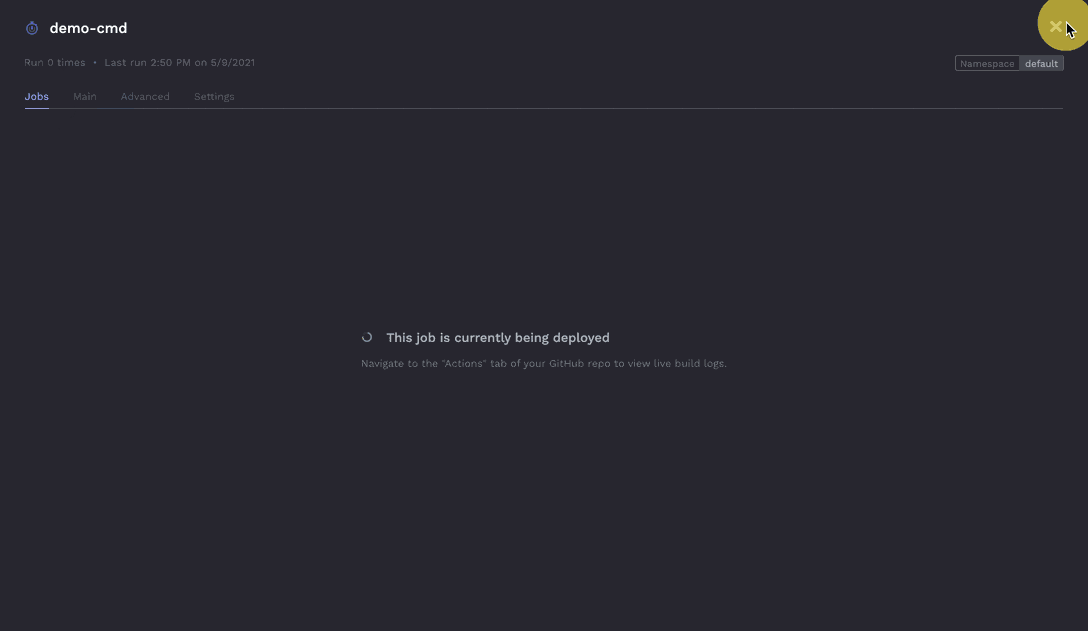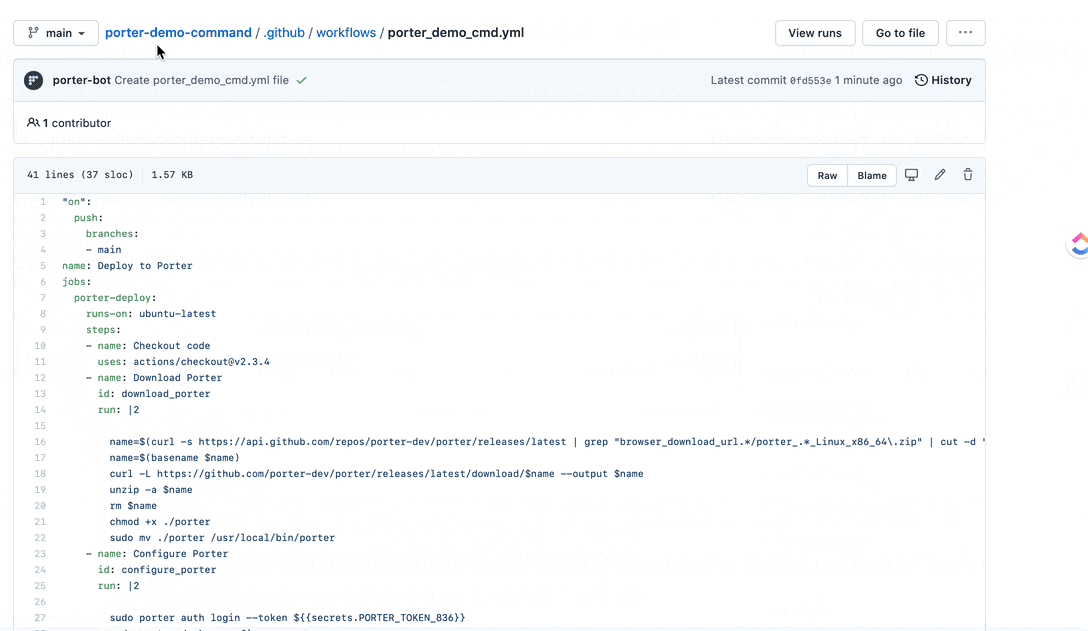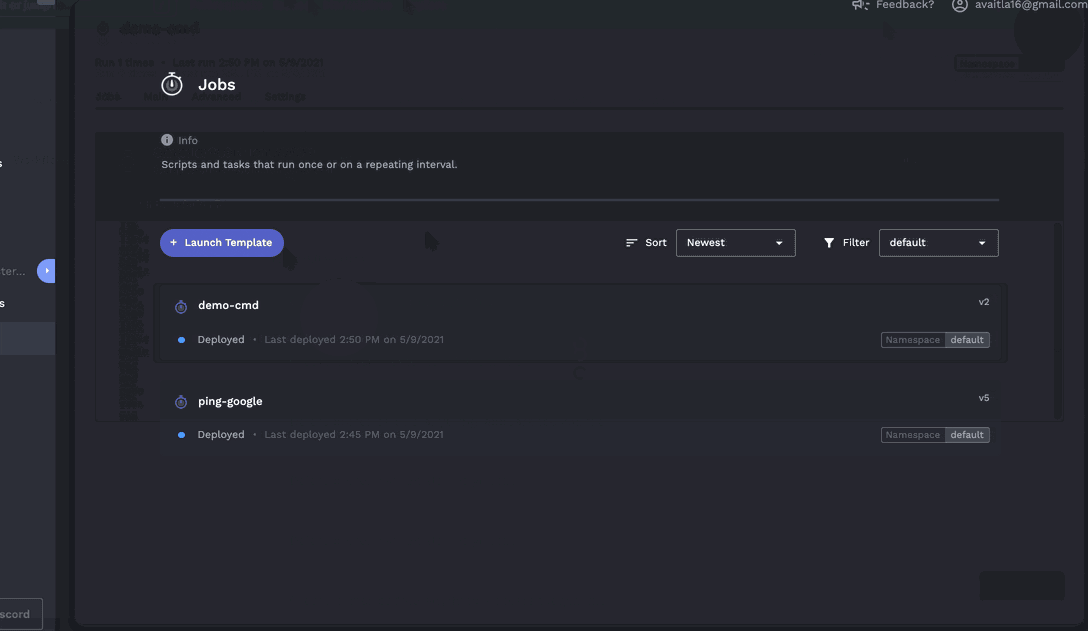
- Jobs can be triggered to run through a secure webhook access (which can be turned off as well at a job by job level).
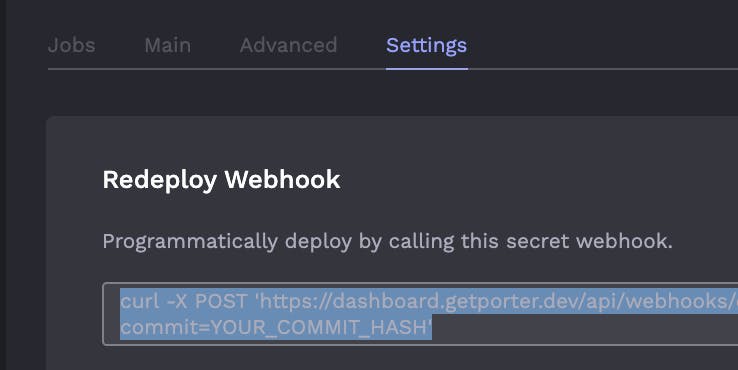
- Jobs should be configurable to only run on demand (when someone clicks them - not triggered by an automated deployment). This is a little bit trickier right now, but I've found a clever way to simulate a job as a cron that will never run (except when its triggered of course). See here: stackoverflow.com/a/57957907
If you set the cron schedule as * * 31 2 * it effectively becomes a job that will never run (except when you go into the UI to run it manually).
One piece of feedback here is that one time jobs and crons really should be considered one in the same because you often need to convert a cron to one time job to troubleshoot and then back once its good. The team has noted this is difficult to do for a few reasons with Kubernetes implementation. However the above hack is a way to do this. Make all jobs into crons with the dummy schedule above and then they're effectively jobs when you need them to be and crons when you give it a sensible schedule again.
Jobs are generally less feature rich than workers or web services, so there's another area of improvement. For instance you can't configure resources (memory / cpu per node), so it is trailing behind the feature sets of web services / workers.
I'm looking forward to seeing what they come up with next.